

What is Webscraping?
Web scraping consists of gathering data available on websites. This can be done manually by a human or by using a bot. It is a process of extracting information and data from a website and transforming information gotten to a structured data for further analysis. Webscraping is also known as web harvesting or web data extraction.
Need for Webscraping
Webscraping helps to get data for use in analyzing trends, performance and price monitoring. It can be used for sentimental analysis of consumers to Getting Insights in News Articles, Market data aggregation , used also in predictive analysis and many Natural Language processing projects. There are various python libraries used in webscraping which include:
- Pattern
- Scrapy
- Beautiful soup
- Requests, Merchandize ,Selenium etc.
Scrapy is a complete webscraping Framework written in python which takes care of downloading HTML, to parsing. Beautiful soup however is a library used for parsing and extracting data from HTML.
Steps Involved In webscraping
- Document Loading/Downloading: Loading the Entire HTML page
- Parsing and Extraction: Interpreting Document and collecting information from the document
- Transformation: Converting the data collected.
For Downloading, The python Request library is used to download the html page. Scrapy has its inbuilt request method.
While parsing the document, there is a need to get familiar with HyperText Markup Language(HTML). HTML is a standard markup language for creating webpages. It consists of Series of elements/tagnames which tells a browser how to display the content. An HTML element is defined by a
<start tag>Content here</end tag>
HTML can be represented as a tree Like structure containing tag names/nodes where there are relationships among nodes which include parent, children , siblings e.t.c
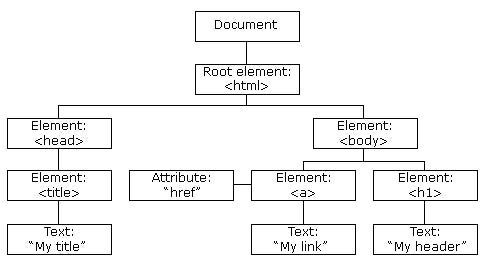
After Downloading, CSS selectors or XPATH Locators are used to extract data from the HTML source
XPath is defined as XML path. It is a syntax or language for finding any element on the web page using the XML path expression. XPath is used to find the location of any element on a webpage using HTML DOM structure.
Getting Started with XPATH locators
Absolute Xpath: It contains the complete path from the Root Element to the desired element.
Relative Xpath: This is more like starting simply by referencing the element you want and go from the particular location. You use always the Relative Path for testing of an element
XPATH Examples with description
I created this HTML script for practice, copy and save as (.html) to work with the Descriptions
<html>
<head><title>Store</title></head>
<body>
<musicshop id="music"><p><h2>MUSIC</p></h2>
<genre><h3><p>Hip-Hop</p></h3>
<ul>
<li>Travis Scott</li>
<li>Pop Smoke</li>
</ul>
</genre>
<genre country="korea"><h3><p>K-pop</p></h3>
<ul>
<li>G Dragon</li>
<li>Super Junior</li>
</ul>
</genre>
</musicshop>
<bookstore id='book'><p><h2>BOOKS</p></h2>
<bookgenre class = "fiction"><p><h3>Fiction</h2></p>
<ul>
<li><booktitle><h5><p>The Beetle</p></h5></booktitle></li>
<li><booktitle><h5><p>The Bell Jar</p></h5></booktitle></li>
<li><booktitle><h5><p>The Book Thief</p></h5></booktitle></bookgenre></li>
</ul>
<bookgenre class="horror"><p><h2>Horror</h2></p>
<ul>
<li><booktitle><h5><p><a href='www.goodreads.com/book/show/3999177-the-bad-seed'>The Bad Seed</a></p></h5></booktitle></li>
<li><booktitle><h5><p>House of Leaves</p></h5></booktitle></li>
<li><booktitle><h5><p>The Hanting of Hill House</p></h5></booktitle></bookgenre></li>
</ul>
</bookstore>
</body>
</html>
The HTML created Generates webpage in Picture Below

To practice XPATH and CSS Locators on browser(Chrome) Link
Press F12 to open up Chrome DevTools.
Elements panel should be opened by default.
Press Ctrl + F to enable DOM searching in the panel.
Type in XPath or CSS selectors to evaluate.
If there are matched elements, they will be highlighted in DOM.
Characters :
- Nodename - Selects nodes with the given name
- "/" starts Selection from root node
- "//" - Ignores Previous Generation of tags and starts from current node that match selection
- "@" - Selects Node wit Given attribute I am going to be using XPATH and the HTML documents above to
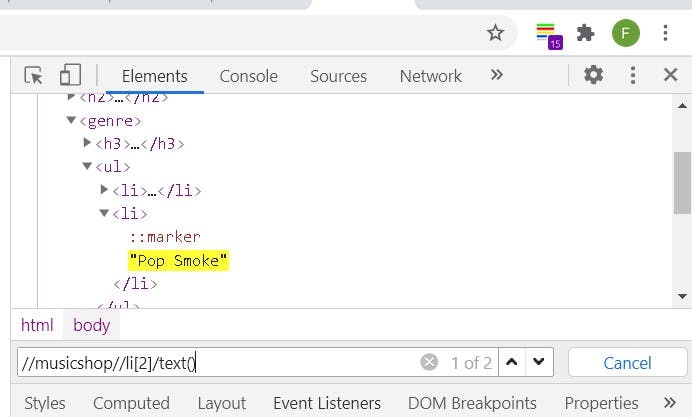
Select the Second HipHop artist
Absolute Path :- /html/body/musicshop/genre/ul/li[2] without specifying index defaults to 1
Relative Path :- //musicshop//li[2]
To extract the name we include /text()
which gives //musicshop//li[2]/text()
 Select by attribute name
Select by attribute name
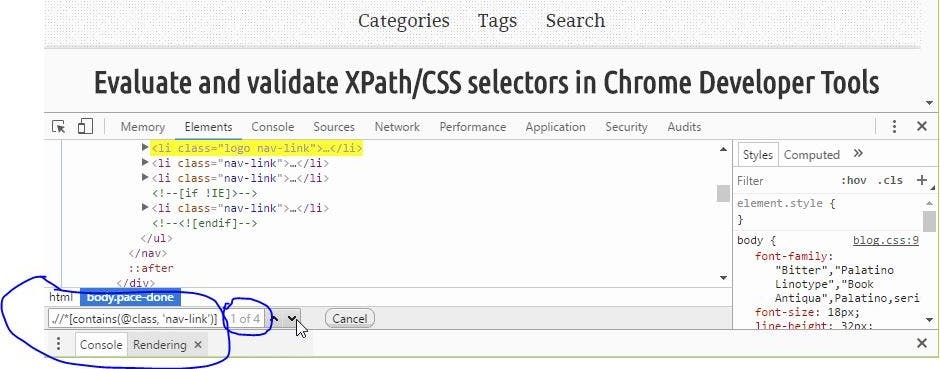
//bookstore/bookgenre[@class='fiction'] ```
//bookstore/bookgenre[contains(@class,'fiction')] can also be used
WebCrawling With Scrapy
We are Going to be Extracting the News Link and Topic from the first page of Nairaland .
First we Inspect Nairaland and the xpath Locator we are going to be using
For Link : //table[@summary='links]//a/@href
For Topic : //table[@summary='links]//a/text() should be the immediate solution, but there are texts
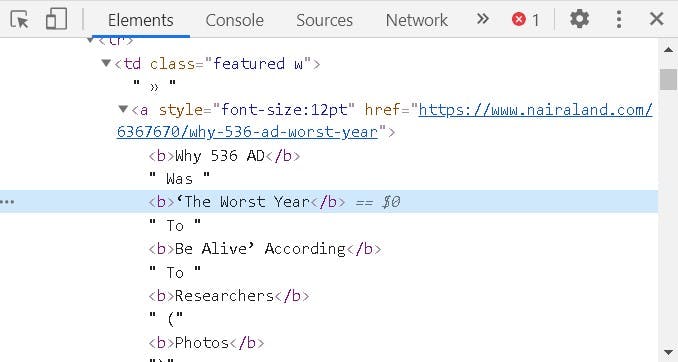 within tags so we will be using
within tags so we will be using //table[contains(@class,'boards')][2]//tr[2]//a[descendant-or-self::text()]
After That, we have the main informations at hand so we Import Our Library
import scrapy
from scrapy.crawler import CrawlerProcess
We create our Spider Class and we inherit a Spider from scrapy
class Spider(scrapy.Spider):
name = 'yourspider'
# start_requests method
def start_requests( self ):
yield scrapy.Request(url = "https://www.nairaland.com/", callback=self.parse)
def parse(self, response):
blocks = response.xpath("//table[contains(@class,'boards')][2]//tr[2]")
News_Titles = blocks.xpath(".//a[descendant-or-self::text()]").extract()
News_Links= blocks.xpath(".//a/@href").extract()
for crs_title, crs_descr in zip( News_Titles, News_Links ):
dc_dict[crs_title] = crs_descr
so we start our crawler process
process = CrawlerProcess()
process.crawl(Spider)
process.start()
print(dc_dict)
Link Below to Access From Colaboratory
That's it. The purpose of this material is to get you started as quickly as possible. I would be Writing about some of my NLP projects Where i Scraped the Internet to gather data. If you'd like to chat and talk about tech in general, feel free to send me a message on Twitter or in the comment section below.